
벌꿀오소리가 되고싶은
[NCIA - 1일차] 하둡 빅데이터 분산시스템 구축 과정 본문
대규모 데이터 확산
2007년 전세계적으로 디지털 정보량이 사용가능안 저장공간을 초과 하기 시작
2011 제타 바이트
단위에 대해서 집고 넘어가자
1024byte
.
.
.
1024GB = 1TB
.
.
.
1024zb = 1YB
하드웨어 발달 보다 데이터 증가 속도가 더 빠르다.
빅데이터란? 기기와 사람이 생성한 컴퓨터 시스템 로그파일, 이메일 메타 데이터 검색엔진 쿼리, 소셜 네트워킹 활동 등에서 수집되 정보
현재의 정의는 IDC - 판단할 수 잇는 규모 기준은 없다 규모가 크고 구조가 다양
분산 컴퓨팅 아키텍쳐란?
하둡
분산 시스템 상에서 대용량 데이터 처리 분석을 지원하는 오픈소스 소프트웨어 프레임워크
구글이 개발한 맵리듀스를 오픈소슬스로 구현한 결과물
야후에서 최초 개발되었으며 지금은 아파치 소프트웨어 재단의 하 프로젝트로 관리 되고 있음
하둡만 쓰게되면 HIVE
메모리기반 스파크를 이용하면 SQL문처럼 이용할 수 잇다.
하둡 설치
virtual merchine 위에 우분투 설치
..
서버한대 사서 우분투 설치
ip설정 192....
하둡바로 설치







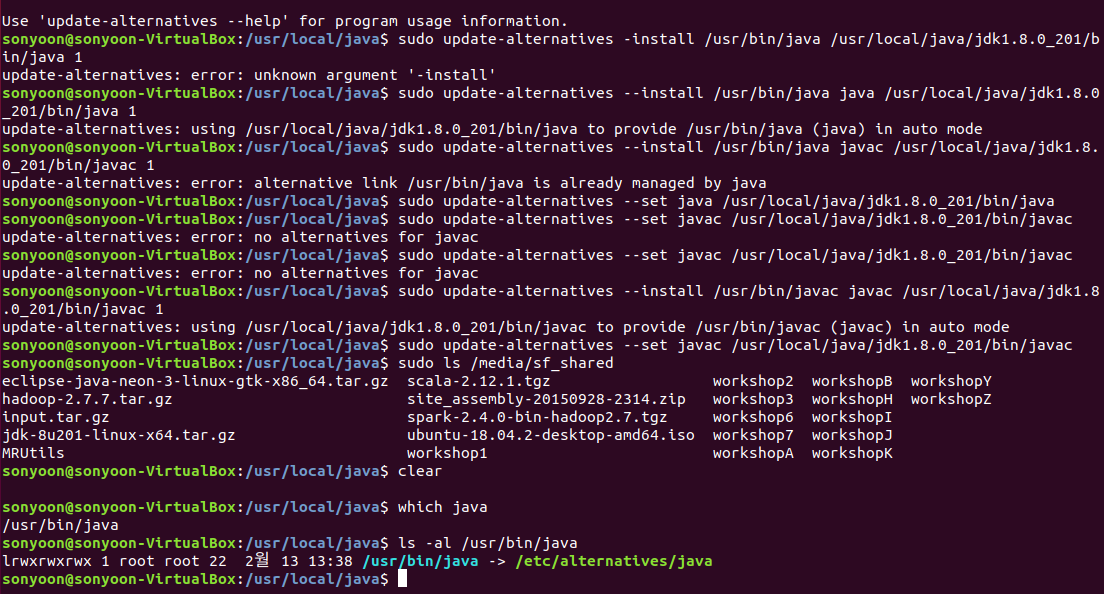
자바 심볼릭 설정
하둡
버전 1: MR + HDFS 맵리듀스와 RM 리소스매니져가 합쳐져 있음
버전2: MR, HDFS가 RS와 분리됨 , YARN 리소스매니져가 기본 제공, 분리되서 확장성이 더 좋아짐
버전3
Hadop 분산 모드로 운영하기 위한 설정 파일들
($HADOOP_HOME/etc/hadoop 안에 있음)
hadoop_env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves

복사 3개
껐다켜도 분산파일시스템 환경이 날아가지 않도록 설정



sudo nano /etc/profile.d/bigdata.sh
'개발 > 개발 이모저모' 카테고리의 다른 글
| AWS EC2 + DOCKER + JENKINS + SPRING BOOT (0) | 2020.03.01 |
|---|---|
| [NCIA - 3일차] 하둡 빅데이터 분산시스템 구축 과정 (0) | 2020.02.15 |
| [NCIA - 2일차] 하둡 빅데이터 분산시스템 구축 과정 (0) | 2020.02.15 |
| Vuex 뷰엑스 (0) | 2020.01.21 |
| AWS Educate - 학생 계정과 일반 계정 연동 서비스 중단 (0) | 2020.01.20 |


